En este apartado mostramos algunos análisis básicos que se pueden hacer con quanteda. Vamos a ir in crescendo, de análisis más básicos de frecuencias a técnicas avanzadas de identificación de patrones. Aquí te incluyo lo que tenemos preparado:
Análisis de frecuencias global
Nube de palabras (no son muy útiles, pero siempre gustan 😏)
Análisis de dispersión léxica
Análisis de concordancias (KWIC)
Comparación de frecuencias relativas entre términos
El análisis de frecuencia de términos nos permite identificar las palabras más comunes, facilitando un primer visionado de aquellos posibles temas recurrentes que pudieran ser interesantes de analizar.
# Extraer el texto de cada entrada diaria y crear una lista planaunified_entries <-unlist(lapply(yearly_entries, function(year) {sapply(year$entries, function(entry)paste(entry, collapse =" ")) })) # Crear una matriz de frecuencias de términos a partir de los textos unificadosdfm_all <-dfm(tokens(unified_entries))# Mostrar las 15 palabras más frecuentestop_words <-topfeatures(dfm_all, n =15)top_words
prison years people like can one even dont
29 29 23 23 23 22 22 21
everyone right russia now just life day
20 19 18 18 18 17 16
🤔¿Qué hemos hecho?
Hemos unificado todo el texto en el objeto unified_entries de manera que ya no distinguimos por año o fecha.
Hemos creado una matriz de frecuencias dfm_all para todo el conjunto de datos contando las veces que aparece cada palabra.
Document-feature matrix of: 6 documents, 1,899 features (84.65% sparse) and 0 docvars.
features
docs january 17th exactly one year ago today came home russia
text1 1 1 2 4 4 1 2 1 1 3
text2 0 0 0 8 4 0 2 0 0 2
text3 0 0 0 0 0 0 0 0 0 1
text4 0 0 0 1 0 0 1 0 2 1
text5 0 0 0 1 0 0 0 0 0 0
text6 1 0 0 5 0 2 0 0 0 0
[ reached max_nfeat ... 1,889 more features ]
Para lograrlo, combinamos varias funciones:
lapply(): Aplica una función a cada elemento de yearly_entries, en este caso, iterando sobre cada año en la lista. Dentro de esta función, procesamos cada entrada diaria para obtener un texto unificado.
sapply(): Anidado dentro de lapply(), sapply() recorre cada entrada diaria de un año específico (representada por year$entries). Nos permite aplicar paste() a cada entrada para unir todas las líneas de la entrada diaria en un solo texto, sin generar sublistas adicionales.
unlist(): Convierte el resultado de lapply() en un vector plano de textos diarios. Esto significa que todos los textos de yearly_entries se colocan en una sola estructura de lista sin anidaciones adicionales, facilitando el análisis posterior.
tokens(): Convierte cada entrada diaria unificada en tokens (es decir, en palabras individuales), lo cual es un paso necesario para aplicar dfm().
dfm(): Crea una matriz de frecuencias de términos (document-feature matrix) a partir de los tokens generados en el paso anterior. En esta matriz, cada fila representa una entrada diaria y cada columna representa una palabra, con valores que indican la frecuencia de cada palabra en cada entrada.
topfeatures(dfm_all, n = 15): Extrae y muestra las 15 palabras más frecuentes en todo el conjunto de datos.
Combinando con el paquete de visualización ggplot2 podríamos crear un gráfico de barras:
library(ggplot2)# Convertir el top 10 en un dataframetop_words_df <-data.frame(word =names(top_words),frequency =as.numeric(top_words))# Crear el gráfico de barrasggplot(top_words_df, aes(x =reorder(word, frequency), y = frequency)) +geom_bar(stat ="identity", fill ="black") +coord_flip() +labs(title ="Top 15 Most Frequent Words",x ="Word",y ="Frequency") +theme_minimal()
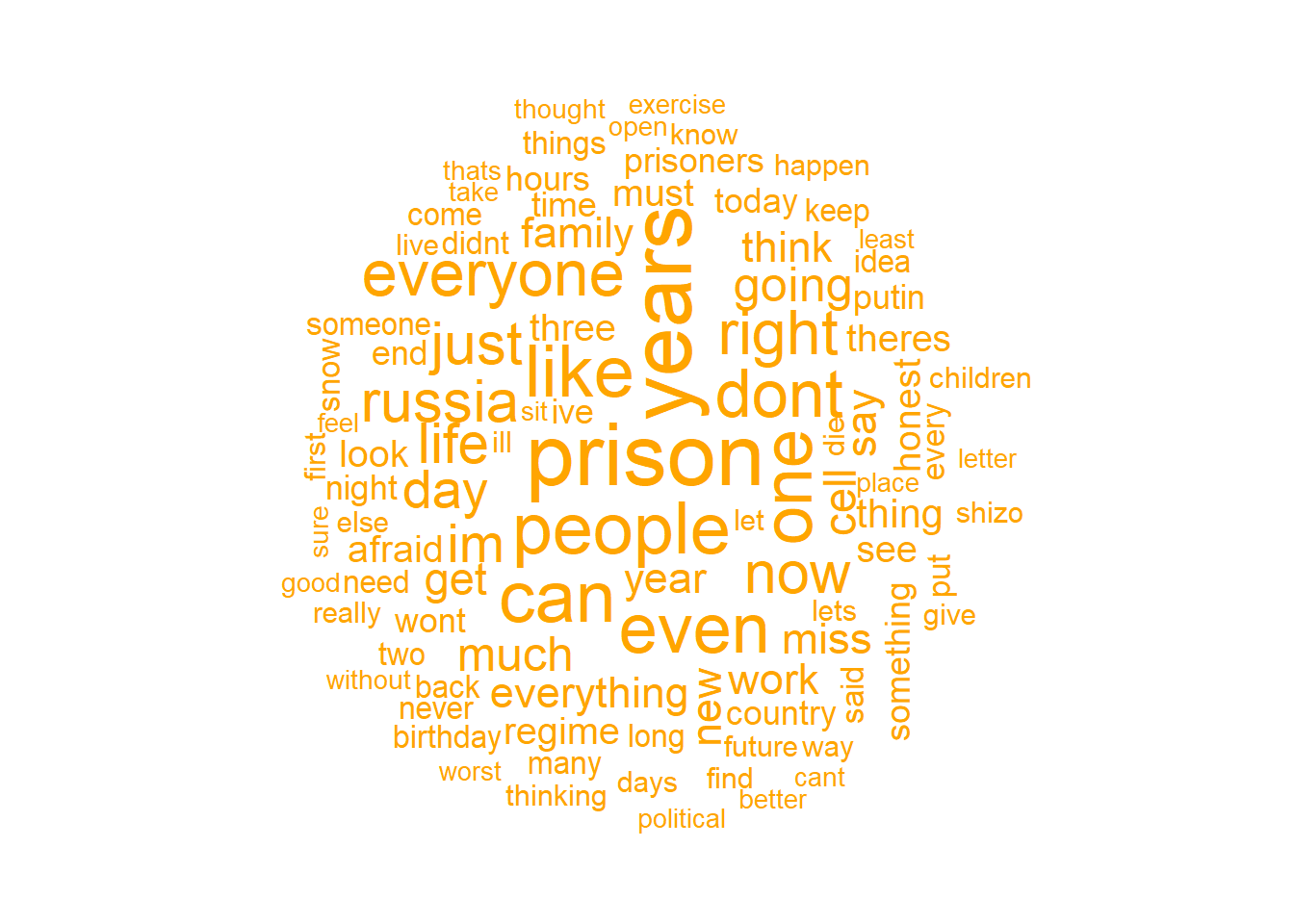
🌥️ Nube de palabras
Una nube de palabras permite identificar visualmente las palabras más frecuentes en el texto. Las palabras más grandes en la nube son las que aparecen con mayor frecuencia, lo cual facilita una comprensión rápida de los términos más relevantes en el contenido.
Usaremos la matriz de frecuencias de términos dfm_all que creamos previamente para generar la nube de palabras.
library(quanteda.textplots)# Generar la nube de palabras a partir de la matriz de frecuenciastextplot_wordcloud(dfm_all, max_words =100, color ="orange")
🤔¿Qué hemos hecho?
textplot_wordcloud() genera una nube de palabras a partir de la matriz de frecuencias dfm_all.
max_words = 100 limita la visualización a las 100 palabras más frecuentes, para que la nube sea más clara y enfocada en los términos clave.
color = asigna el color de las palabras para una visualización consistente.
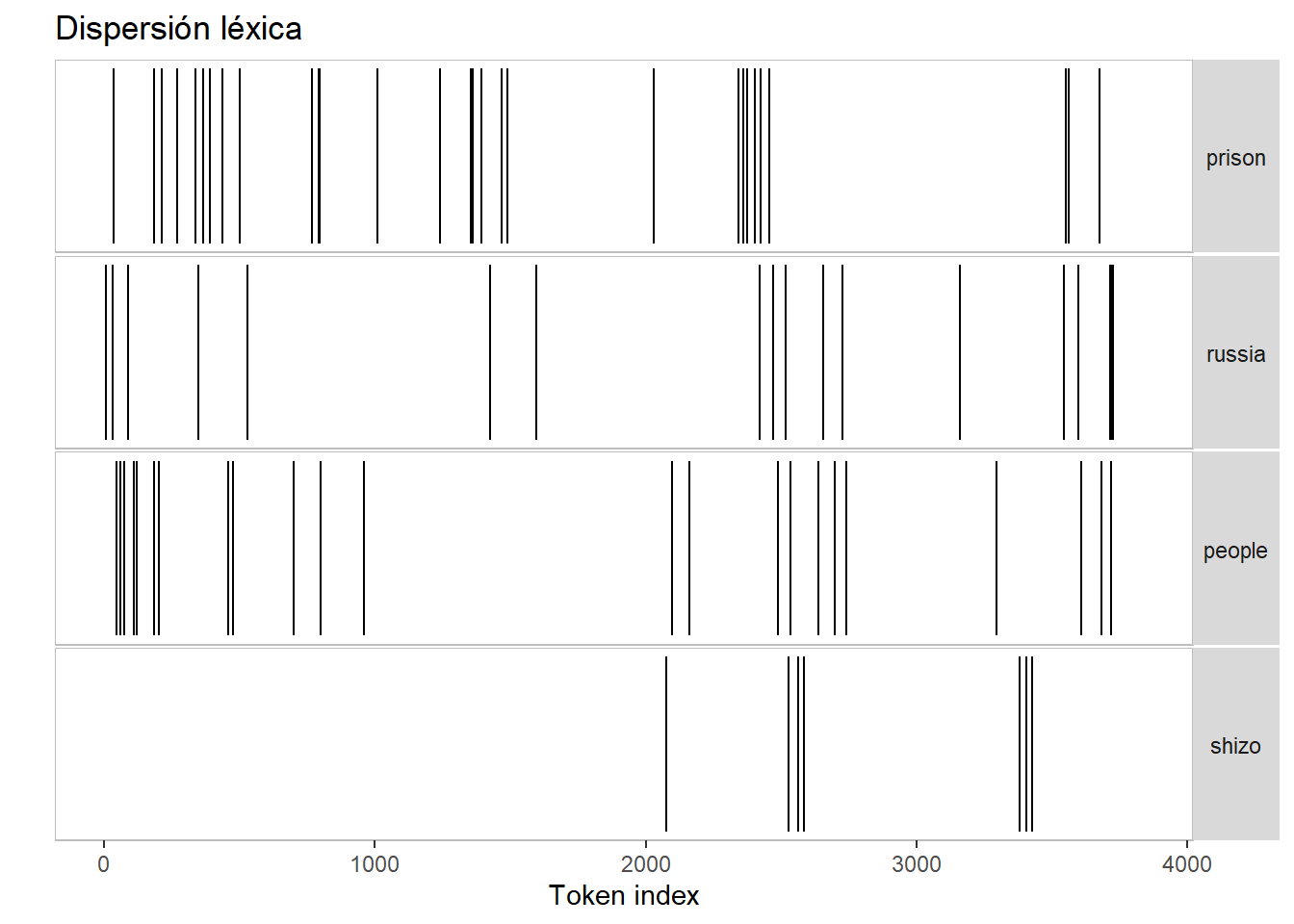
📍Análisis de dispersión léxica
La dispersión léxica nos permite ver en qué partes del texto aparecen ciertas palabras clave. Esto puede ser particularmente útil si queremos rastrear cómo cambia el uso de ciertos términos importantes a lo largo del tiempo o en diferentes contextos.
Usaremos la función textplot_xray() de quanteda.textplots para generar un gráfico de dispersión de las palabras clave en el conjunto de datos. Para ello debermos instalar primero este paquete.
# Librería necesarialibrary(quanteda.textplots)# Palabras clave para el análisis de dispersión léxicakeywords <-c("prison", "russia", "people", "shizo")# Unificar todas las entradas en un solo textofull_text <-paste(unified_entries, collapse =" ")# Crear tokens a partir del texto completotokens_full_text <-tokens(full_text)# Generar gráfico de dispersión léxica para todo el textotextplot_xray(kwic(tokens_full_text, pattern = keywords)) +labs(title ="Dispersión léxica")
🤔¿Qué hemos hecho?
Hemos seleccionado los términso a analizar basándonos en el análisis de frecuencias anterior
Con la función paste(..., collapse = " ") hemos unido todas las entradas en el objeto full_text, formando un solo texto continuo sin distinguir por año o entrada.
Hemos creado los tokens a partir del texto unificado con la función tokens() para poder trabajar a nivel de palabras
La función kwick() nos sirve para extraer las posiciones de las palabras clave del texto completo.
textplot_xray() viene del paquete quanteda.textplots y nos permite visualizar la dispersión léxica.
🔍 Análisis de concordancias (KWIC)
Este análisis muestra cada aparición de las palabras clave junto con el contexto inmediato, lo que permite estudiar cómo se usan ciertos términos en diferentes partes del texto.
En este ejemplo vamos a analizar las palabras que preceden y anteceden al término shizo.
# Extraer concordancias de las palabras claveconcordancias <-kwic(tokens_full_text, pattern ="shizo", window =2)print(concordancias)
Keyword-in-context with 7 matches.
[text1, 2077] give idea | shizo | place sit
[text1, 2528] now add | shizo | list places
[text1, 2562] requires sent | shizo | must examined
[text1, 2584] weve put | shizo | keep cracking
[text1, 3381] just keeping | shizo | overoptimistic also
[text1, 3405] seven days | shizo | wonderful detail
[text1, 3428] warmer afternoon | shizo | howeverexercise starts
🤔¿Qué hemos hecho?
Aplicamos la función kwic()para extraer las concordancias de las palabras clave. Es decir, el texto anterior y posterior a estos términos.
El parámetro window = especifica el número de palabras que se mostrarán antes y después de cada palabra calve, l oque proporciona un contexto breve que nos permite inspeccionar de manera manual el sentido de cada palabra.
🧩 Topic Modeling
El análisis de temas, o topic modeling, es una técnica de procesamiento de lenguaje natural que identifica patrones ocultos en un conjunto de textos. Su objetivo es descubrir temas latentes que aparecen recurrentemente, agrupando palabras que suelen aparecer juntas. Cada tema representa un conjunto de palabras que tienden a co-ocurrir, permitiéndonos inferir posibles temas o conceptos sin necesidad de leer todo el texto.
El modelo de temas que utilizaremos, llamado Latent Dirichlet Allocation (LDA), funciona tratando cada documento como una combinación de varios temas, y cada tema como una combinación de palabras. Así, LDA genera temas representativos del contenido general de los textos, lo cual es útil para identificar patrones y estructura temática en grandes volúmenes de texto.
En primer lugar vamos refinar nuestra matriz de frecuencias dfm_all eliminando términos poco frecuentes
dfm_topics <-dfm_trim(dfm_all, min_termfreq =5)
En este caso min_termfreq = 5: Elimina términos que aparecen menos de 5 veces en todo el conjunto de documentos.
Vamos a ver cómo se ha reducido el set de términos:
length(dfm_all) # total de términos
[1] 30384
length(dfm_topics) # total una vez eliminados los poco frecuentes
[1] 2432
Ahora vamos a usar nuestra nueva matriz de frecuencias dfm_topics para aplicar nuestro modelo de LDA. Importante, aquí necesitaremos tener instalado el paquete tm y el paquete topicmodels.
library(tm)library(topicmodels)# Convertir la matriz dfm a formato compatible con LDAdfm_topics_lda <-convert(dfm_topics, to ="topicmodels")# Definir el número de temasnum_topics <-4# Ajusta el número de temas según el análisis deseado# Ajustar el modelo LDAlda_model <-LDA(dfm_topics_lda, k = num_topics, control =list(seed =1234))# Obtener las palabras clave de cada tematerms(lda_model, 10) # Muestra las 10 palabras más representativas de cada tema
La función convert() transforma nuestra matriz de frecuencias en un formato entendible por el paquete topicmodels para poder modelarlo.
Elegimos el número de topics con los que queremos trabajar. Esta parte suele ser una decisión informada tras hacer varias pruebas. En nuestro caso, me quedaré con 3 topics.
Entreno al modelo con mis datos con la función LDA(). Para permitir reproducibilidad del análisis utilizo el parámetro control= para establecer una semilla para el generador de números aleatorios que emplea el algoritmo.
Footnotes
El topic modeling (modelado de tópicos) es una técnica de análisis de texto que identifica temas latentes dentro de un conjunto de documentos. Agrupa palabras que tienden a aparecer juntas, permitiendo descubrir patrones temáticos y estructuras ocultas en el texto.